Introduction
It is a general idea that: different from how a computer process the task, humans will not always choose the shortest path to reach destination. And at the first glance, one might consider that different people will link two words in various way according to their prior knowledge.
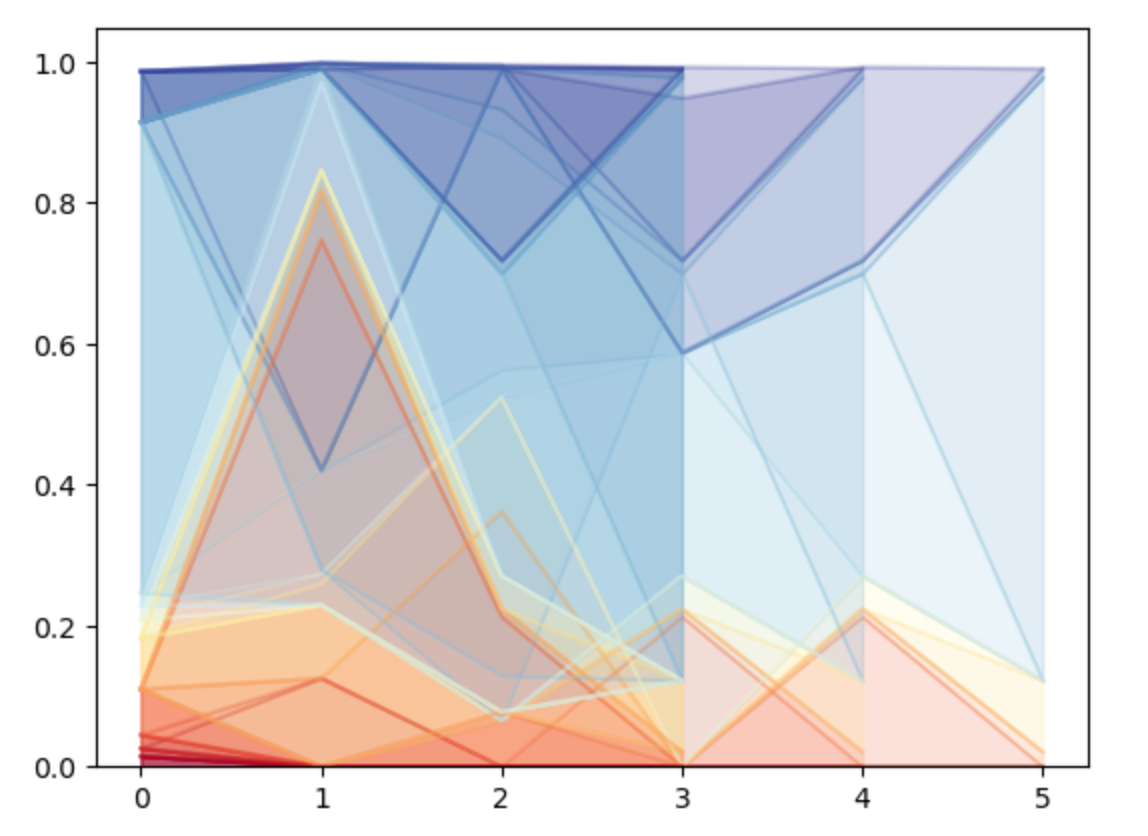
However, here we want to investigate whether there is a common and general pattern in human’s formation of the word navigating. During the way-finding procedure, do human generate fantastic ideas to finish the word to word linking? Or though people finish the task in various path, there still exist a potential pattern in human’s mind to link two topic words.
We carry out our analysis by using the dataset collecting through the human-computation game Wikispeedia.
Research Question A
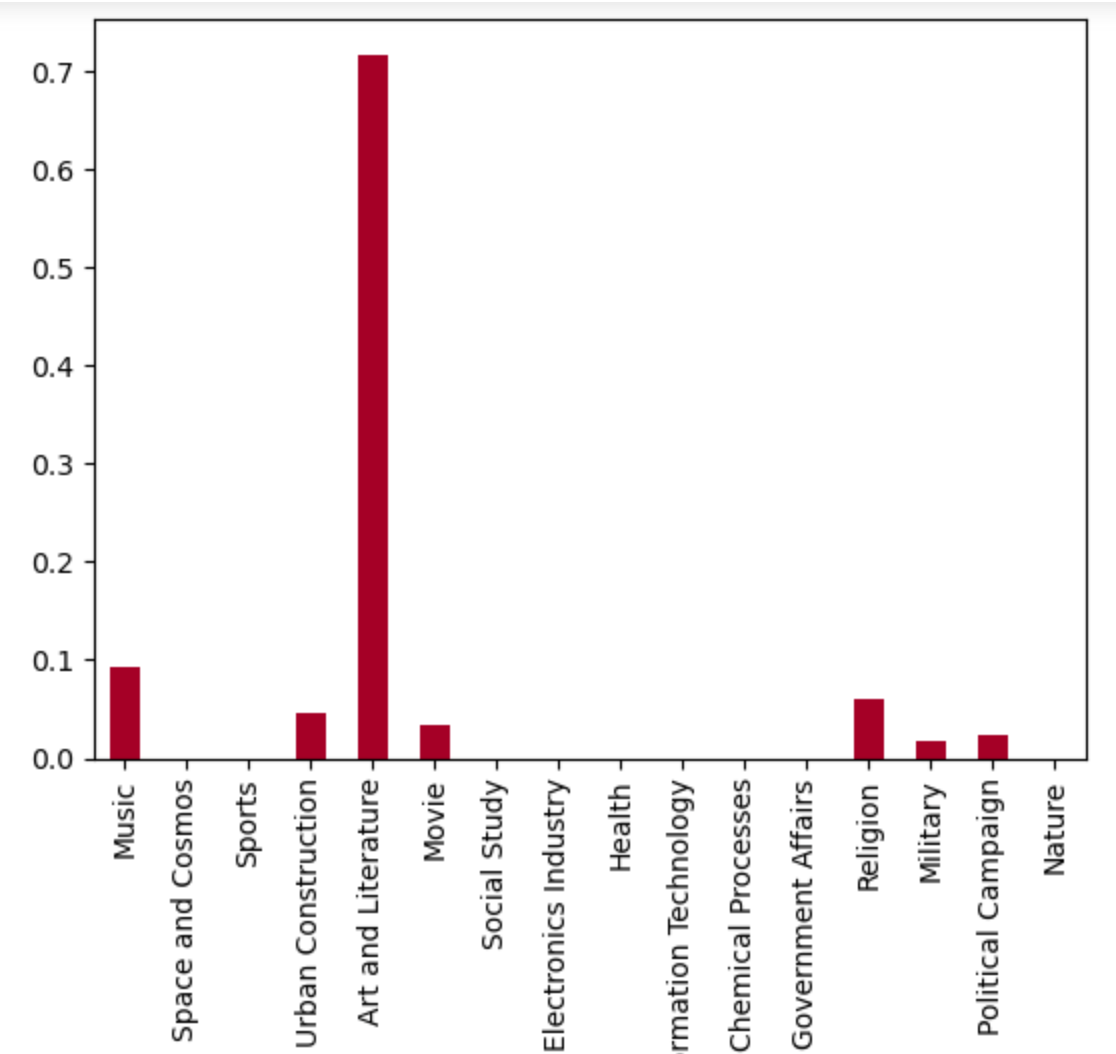
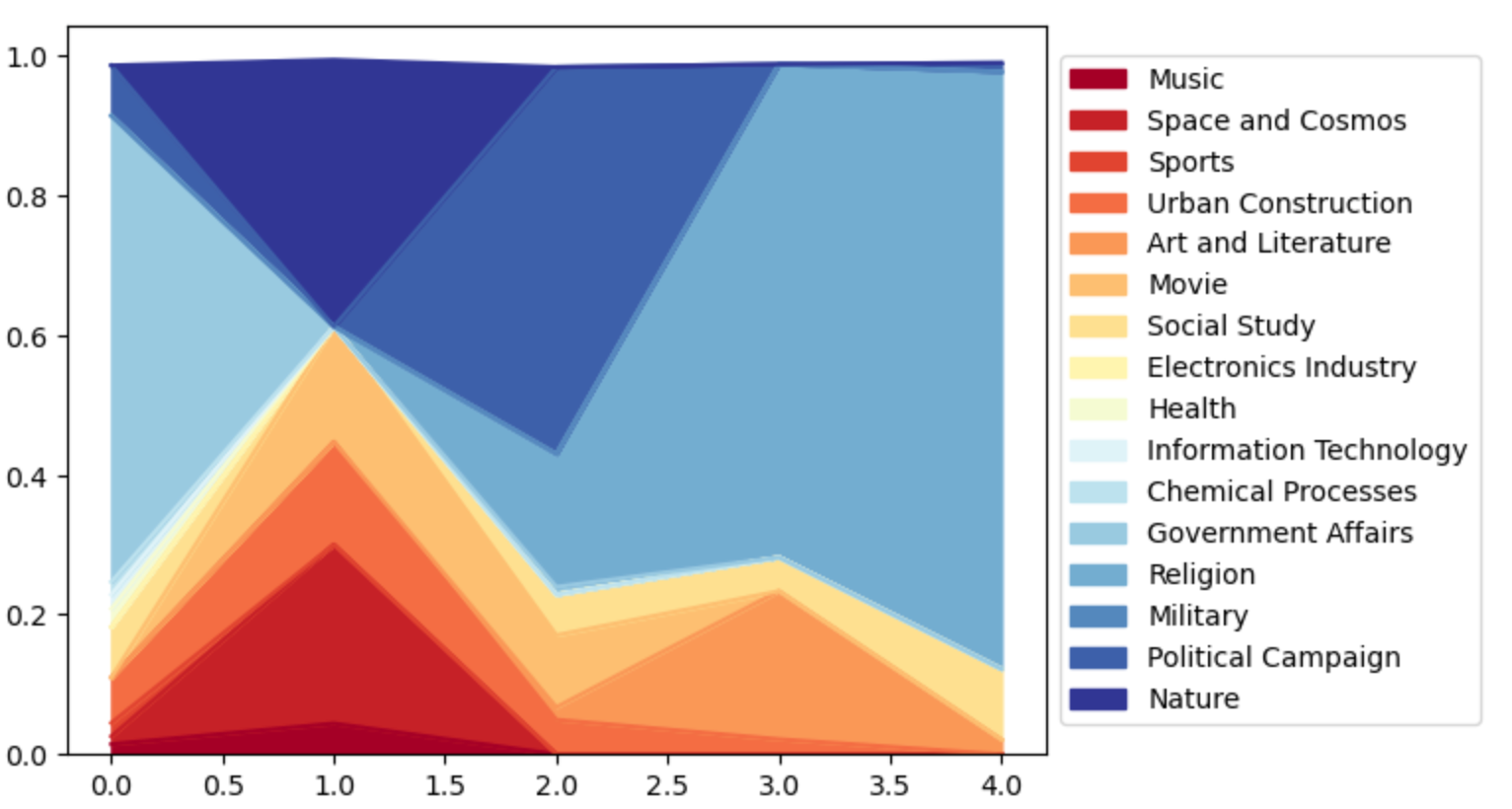
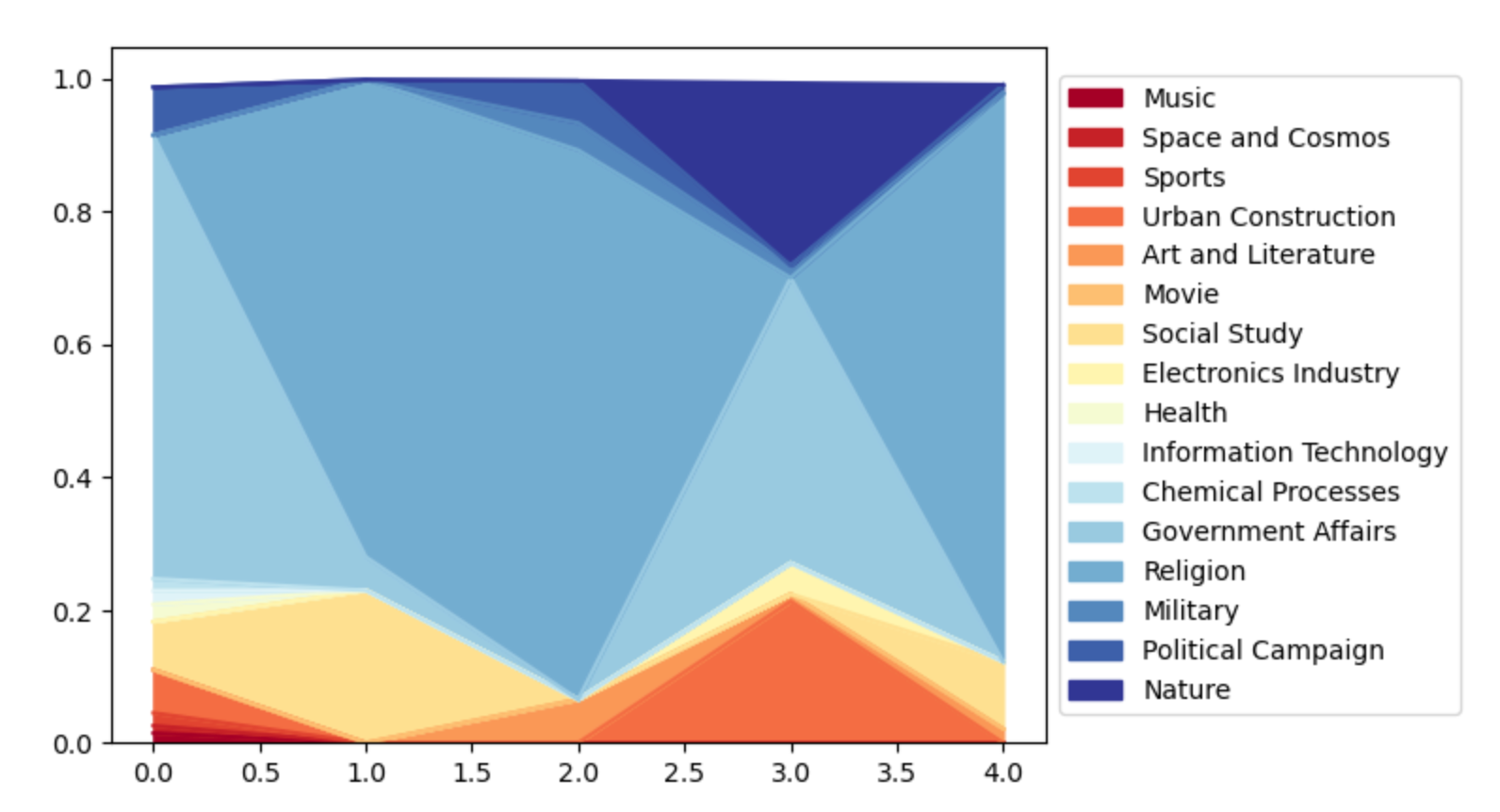
Is there any specific pattern change in articles’ topic component, during the clicking process? For example, when navigating from ‘Zebra’ to ‘French Revolution’, there is a hypothesis that the elements of animals may decrease, and the elements of history or politics would increase through the path. Does the ‘Zebra & French Revolution‘ hypothesis mentioned above or similar phenomenon hold?
Research Question B
Are there any external factors that influence people’s choice of clicking, i.e. contents on HTML pages?
1. Do people tend to click links in an easy sentence or a professional sentence?
2. Do people tend to click links that show up in the first a few lines of the article or links that have concentrated distribution in the webpage?